

Mastering Web Scraping with Python and BeautifulSoup: A Beginner's Guide

Hi, I’m Richa — a Senior Frontend Engineer with 5+ years of experience building scalable, production-grade web interfaces for enterprise and consumer applications. I work primarily with React, TypeScript, and modern frontend architectures, focusing on component systems, performance, and maintainability. Most of my experience comes from building real-world products in regulated domains like banking and insurance, where clarity, reliability, and long-term ownership matter more than quick demos. Through this blog, I write about frontend engineering fundamentals, scalable UI design, problem-solving, and the lessons I’ve learned working on large codebases. My goal is to share practical insights — not shortcuts — for developers who want to grow strong engineering foundations. I also mentor early-career developers and strongly believe that curiosity, asking the right questions, and understanding why something works are more important than memorizing tools. If you’re serious about improving as an engineer, you’re in the right place.
Hey coders👩💻👨💻! It's been a few months since I last posted on this blog, but I'm back with an exciting topic that I've been diving into recently: web scraping.
If you're wondering what web scraping is and how you can use Python and BeautifulSoup (often referred to as BS4) to get data from websites, you're in the right place.

🐱👤What is Web Scraping?
Web scraping is the process of automatically extracting data from websites. This data can include text, images, tables, and more. Imagine being able to gather news headlines, product prices, weather forecasts, or any other information from the web without manually copying and pasting.
🐱🏍Prerequisites
Before we dive into web scraping with Python and BeautifulSoup, you'll need a few things:
Python Installed: If you don't have Python installed on your computer, download it from the official website https://www.python.org/downloads/ and follow the installation instructions.
BeautifulSoup (BS4): This Python library makes web scraping easy. You can install it using
pip:pip install beautifulsoup4You can find the official documentation for BeautifulSoup (BS4) on the following website:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
This documentation provides detailed information about how to use BeautifulSoup for web scraping and parsing HTML and XML documents. It includes examples, explanations of various methods and functions and best practices for web scraping. It's an excellent resource to accompany your learning journey.
HTML Basics: A basic understanding of HTML structure will be helpful. Don't worry; you don't need to be an expert. Knowing the difference between tags, attributes, and elements will suffice.
✨Getting Started with Web Scraping

Getting Started with Web Scraping
1. Choose a Website to Scrape
For this beginner's guide, let's pick a simple website to scrape. I'll use a hypothetical website that lists information about Movies. We'll extract allMovie in txt.
2. Inspect the Web Page
Before scraping, it's crucial to understand the structure of the web page you want to extract data from. Right-click on the web page and select "Inspect" (or press Ctrl+Shift+I or Cmd+Option+I on Mac) to open the browser's Developer Tools. This will show you the HTML source code of the page.
3. Use BeautifulSoup to Parse HTML
Here's where BeautifulSoup comes into play. We'll use it to parse the HTML and extract the data we need. First, import BeautifulSoup in your Python script:
from bs4 import BeautifulSoup
4. Send an HTTP Request
To fetch the web page's HTML content, you can use the requests library. If you don't have it installed, you can install it with pip:
pip install requests
Let's understand this with a practical example. We'll work on a small project together so that you can grasp the concepts more effectively.

# Import necessary libraries
from bs4 import BeautifulSoup
import requests
# Define the URL of the website containing the movie transcript
website = 'https://subslikescript.com/movie/Titanic-120338'
# Send an HTTP GET request to the website and store the response
result = requests.get(website)
# Get the HTML content of the website
content = result.text
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(content, 'lxml')
# Uncomment the line below to see the nicely formatted HTML (for debugging purposes)
# print(soup.prettify())
# Locate the HTML element that contains the title and transcript of the movie
box = soup.find('article', class_='main-article')
# Locate the title of the movie (it's within an <h1> tag)
title = box.find('h1').get_text()
# Locate and extract the transcript of the movie (it's within a <div> with class 'full-script')
transcript = box.find('div', class_='full-script').get_text(strip=True, separator=' ')
# Export the extracted data (transcript) to a text file with the same name as the movie title
with open(f'{title}.txt', 'w', encoding='utf-8') as file:
file.write(transcript)
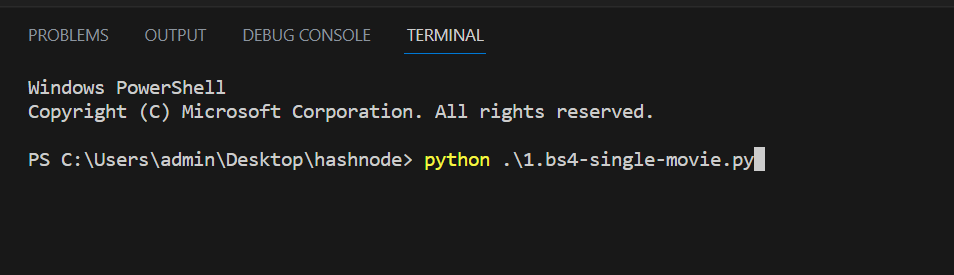
No matter what name you give to the file, if you run the code in the terminal, it will create a text file with the Titanic movie script

from bs4 import BeautifulSoup
import requests
#####################################################
# Extracting the links of multiple movie transcripts
#####################################################
# How To Get The HTML
root = 'https://subslikescript.com' # this is the homepage of the website
website = f'{root}/movies' # concatenating the homepage with the movies section
result = requests.get(website)
content = result.text
soup = BeautifulSoup(content, 'lxml')
# print(soup.prettify()) # prints the HTML of the website
# Locate the box that contains a list of movies
box = soup.find('article', class_='main-article')
# Store each link in "links" list (href doesn't consider root aka "homepage", so we have to concatenate it later)
links = []
for link in box.find_all('a', href=True): # find_all returns a list
links.append(link['href'])
#################################################
# Extracting the movie transcript
#################################################
# Loop through the "links" list and sending a request to each link
for link in links:
result = requests.get(f'{root}/{link}')
content = result.text
soup = BeautifulSoup(content, 'lxml')
# Locate the box that contains title and transcript
box = soup.find('article', class_='main-article')
# Locate title and transcript
title = box.find('h1').get_text()
title = ''.join(title.split('/'))
transcript = box.find('div', class_='full-script').get_text(strip=True, separator=' ')
# Exporting data in a text file with the "title" name
with open(f'{title}.txt', 'w', encoding='utf-8') as file:
file.write(transcript)
In this code:
Step 1 (Extracting Links to Multiple Movie Transcripts):
We start by defining the root URL of the website and creating a URL for the movies section by appending it to the root URL.
We send an HTTP GET request to the movies section and retrieve the HTML content.
A BeautifulSoup object is created to parse the HTML content.
We locate the section that contains a list of movie links within the parsed HTML.
We store each movie's link in the "links" list, making sure to add the root URL to each link since href attributes don't include the root.
Step 2 (Extracting Movie Transcripts):
We loop through the "links" list and send an HTTP GET request to each movie's transcript link, creating the complete URL by combining the root URL with the movie's transcript link.
For each movie, we retrieve the HTML content of the transcript page, create a new BeautifulSoup object, and locate the section that contains the title and transcript.
We extract the title of the movie, remove any forward slashes from it (as they can't be used in file names), and locate and extract the transcript of the movie.
Finally, we export the extracted data (transcript) into a text file, naming the file after the movie's title.
This code automates the process of scraping and saving movie transcripts from a website, generating separate text files for each movie's transcript.


# Import the necessary libraries
from bs4 import BeautifulSoup
import requests
#####################################################
# Step 1: Extracting Links from Pagination Bar
#####################################################
# Define the root URL of the website
root = 'https://subslikescript.com' # This is the homepage of the website
# Create the URL for the movies "letter-X" section (you can choose any section)
website = f'{root}/movies_letter-X'
# Send an HTTP GET request to the movies "letter-X" section
result = requests.get(website)
# Get the HTML content of the page
content = result.text
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(content, 'lxml')
# Locate the box that contains the pagination bar
pagination = soup.find('ul', class_='pagination')
# Find all the pages in the pagination bar
pages = pagination.find_all('li', class_='page-item')
# Get the number of the last page (this represents the number of pages in the "letter-X" section)
last_page = pages[-2].text
##################################################################################
# Step 2: Extracting Links to Movie Transcripts from Multiple Pages
##################################################################################
# Loop through all the pages and send a request to each page
for page in range(1, int(last_page) + 1):
# Create the URL for the current page by adding the page number as a query parameter
page_url = f'{website}?page={page}'
# Send an HTTP GET request to the current page
result = requests.get(page_url)
# Get the HTML content of the current page
content = result.text
# Create a BeautifulSoup object to parse the HTML content of the current page
soup = BeautifulSoup(content, 'lxml')
# Locate the box that contains a list of movies
box = soup.find('article', class_='main-article')
# Store each movie link in the "links" list (href doesn't include the root URL, so we'll add it later)
links = []
for link in box.find_all('a', href=True): # find_all returns a list
links.append(link['href'])
#################################################
# Step 3: Extracting Movie Transcripts
#################################################
for link in links:
try:
# Create the complete URL for the current movie by combining the root URL with the movie's link
movie_url = f'{root}/{link}'
# Send an HTTP GET request to the current movie's transcript page
result = requests.get(movie_url)
# Get the HTML content of the movie's transcript page
content = result.text
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(content, 'lxml')
# Locate the box that contains the title and transcript
box = soup.find('article', class_='main-article')
# Locate the title of the movie
title = box.find('h1').get_text()
# Remove any forward slashes from the title (as they can't be used in file names)
title = ''.join(title.split('/'))
# Locate and extract the transcript of the movie
transcript = box.find('div', class_='full-script').get_text(strip=True, separator=' ')
# Export the data into a text file with the title as the file name
with open(f'{title}.txt', 'w') as file:
file.write(transcript)
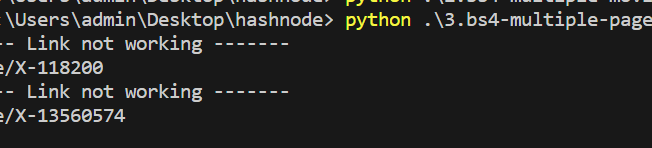
except:
print('------ Link not working -------')
print(link)
In this code:
Step 1 (Extracting Links from Pagination Bar):
We start by defining the root URL of the website and create the URL for a specific section (in this case, movies starting with the letter "X").
An HTTP GET request is sent to the page, and its HTML content is retrieved.
We create a BeautifulSoup object to parse the HTML content and locate the pagination bar.
We find all the pages in the pagination bar and determine the number of the last page, which represents the total number of pages in the "letter-X" section.
Step 2 (Extracting Links to Movie Transcripts from Multiple Pages):
We loop through all the pages (from 1 to the last page) and send an HTTP GET request to each page, appending the page number as a query parameter.
For each page, we retrieve its HTML content, create a BeautifulSoup object, and locate the box containing a list of movies.
We store each movie's link in the "links" list, making sure to add the root URL to each link since href attributes don't include the root.
Step 3 (Extracting Movie Transcripts):
For each movie link in the "links" list, we send an HTTP GET request to the movie's transcript page, create a BeautifulSoup object, and locate the title and transcript.
We extract the title of the movie, remove any forward slashes from it (as they can't be used in file names), and locate and extract the transcript of the movie.
Finally, we export the extracted data (transcript) into a text file, naming the file after the movie's title. If any errors occur during this process, we print a message indicating that the link is not working.
This code allows you to scrape movie transcripts from multiple pages with pagination, ensuring that you don't miss any movies listed on the website.
🎯 Wrap Up and Stay Connected!
Congratulations 🐱💻 on completing this beginner's guide to web scraping with Python and BeautifulSoup!
You've learned how to extract valuable data from websites, and the possibilities are endless. You can save the extracted data to files, databases, or use it for in-depth analysis, depending on your project's requirements.
But remember, this is just the beginning of your web scraping journey. There are more advanced topics to explore, such as handling pagination, dealing with dynamic websites, and implementing techniques to avoid being banned by websites—so stay curious and keep learning!
I*'m thrilled to be back on the blogging scene, and I'm committed to sharing valuable knowledge and insights with you. If you found this guide helpful, don't forget to like and share my blog. Feel free to leave comments and questions; I'll be here to assist you on your web scraping adventure.*
And remember, stay tuned for weekly web scraping knowledge-sharing right here! Together, we'll dive deeper into the world of web scraping and uncover exciting opportunities for data acquisition and analysis. Happy scraping, and see you in the next blog post! 🚀📚





